Reinforcement Learning Aided Model Predictive Controller for Autonomous Vehicle Lateral Control
A nonlinear model predictive controller (NMPC) coupled with a reinforcement learning (RL) model that can be applied to lateral control tasks for autonomous vehicles. For a more in-depth discussion of the project, please find the paper here.

we propose to use a RL model to dynamically select the weights of the NMPC objective function while performing real-time lateral control of the autonomous vehicle (we call this RL-NMPC). The RL weight-search model is trained in a simulator using only one reference path, and is validated first in a simulation environment and then on a real Lincoln MKZ vehicle; the RL-NMPC achieved considerably better performance in lateral tracking during simulation and on-board tests.
Training Pipeline

The training cycle for the RL weight search module. The output of the RL are a set of matrices (or scalars) that is used in the cost function of the MPC; the solution of the MPC (steering angle ut) is then executed in the simulator; and the simulator returns the observations of the environment and calculated reward r to the RL module which is updated using the information feedback from the simulator.

To boost the training efficiency and the utilization of Graphic Processing Unit (GPU), multiple independent simulations are run in parallel. Multi-threaded training can perform updates asynchronously, by using one global network and multiple local networks. During training, each agent is controlled by one local network to collect experience tuples in its own independent simulation; and the global network can be updated as soon as one of the local agent completes experience collection without the need to wait for other agents to complete.
A simple demonstration for the multi-worker RL training pipeline using OpenAI Gym environment and asynchronous version of PPO.
Simulated Results
The tests are run on four different maps, all from recorded waypoints of test tracks and public roads. For simulation tests we tested the performance of all three RL algorithms: DDPG, TD3, and PPO.

For lateral error tracking, all three RL models outperform the baseline parameters.



The above three plots show how the MPC weight matrices change during simulation tests at different road segments.
On-board Deployment
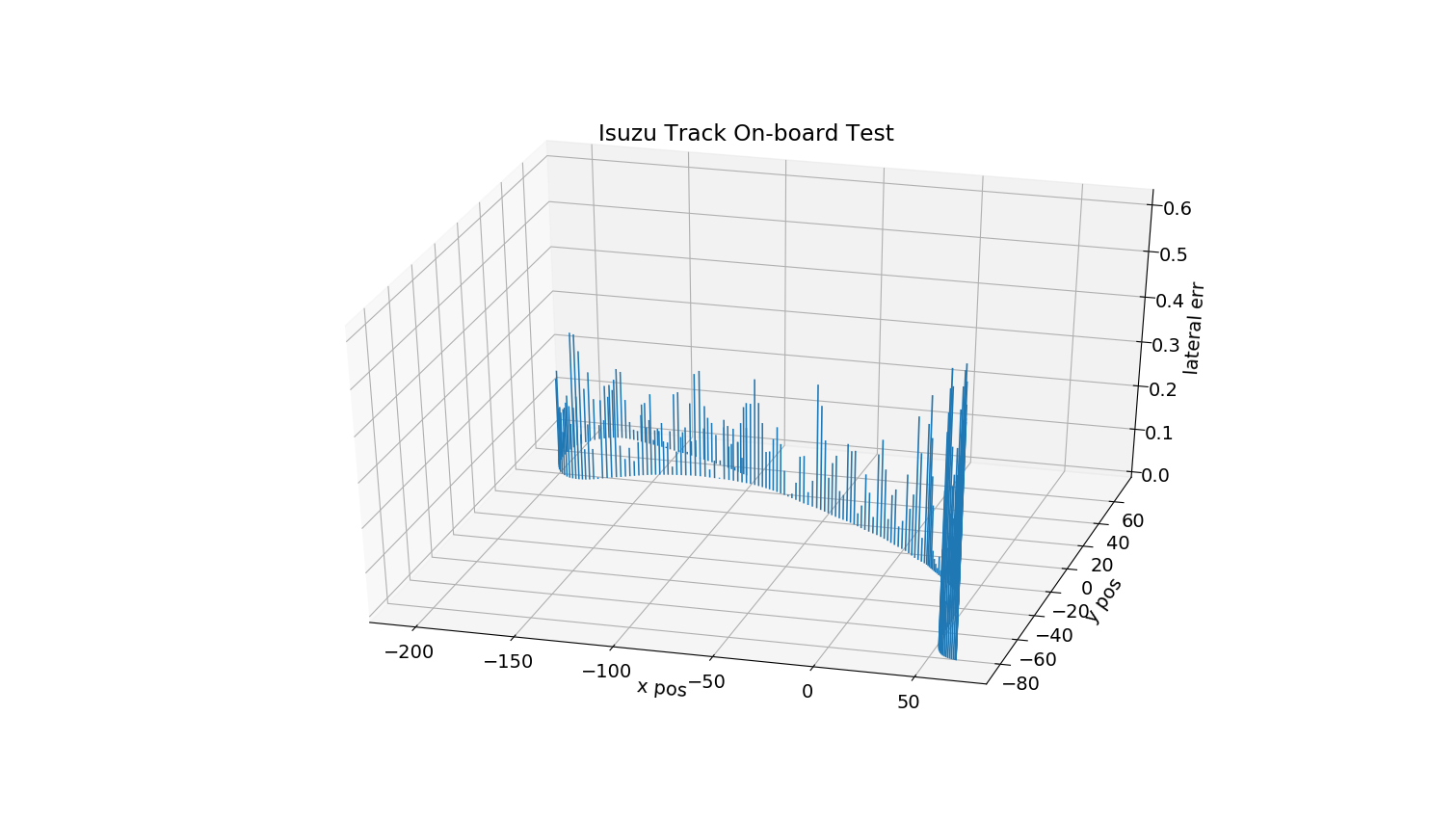
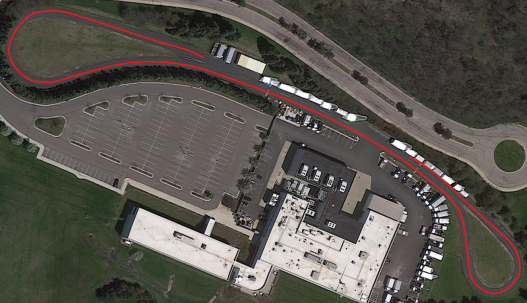
The on-board testing of the weight selection scheme is done on a real Lincoln MKZ vehicle. The vehicle is modified so that its low level controller can communicate with the host laptop via Robot Operating System (ROS). The RL model is run on the host laptop along with the MPC, and then the computed steering angle will be sent to the low level controller on the vehicle in the form of ROS message; similarly, the states of the vehicle are sent to the host laptop via ROS messages. The distance from the front and rear axles to the vehicle’s center of gravity are 1.2m and 1.65m, respectively; additionally, the vehicle has a full drive-by-wire system that can communicate with the host computer via ROS, a Polynav 2000P GNSS-inertial system, a Calmcar front view camera, and a Dspace Autera computing unit. The on-board test is carried out on the test track in Isuzu Technical Center of America facility