Training and Deployment Pipeline for Learning Quadruped Locomotion
Training and deploying visuomotor RL model for robot dog control to enhance its mobility. The GitHub link to the repo (still being updated) can be found here
Task Videos
One single visuomotor RL policy (the realsense camera is out of frame) enables the Unitree GO1 robot dog to complete different tasks that cannot be accomplished by Unitree's official low-level controller, as shown below.
The Unitree Go1 in all three of the following videos are controlled by our visuomotor policy (vision transformer as visual encoder), the RL algorithm we used is PPO.
Adjust Its Height To Go Through Obstacles
Four Modes of Gaits
Traverse Uneven Terrain
Deployment Pipeline
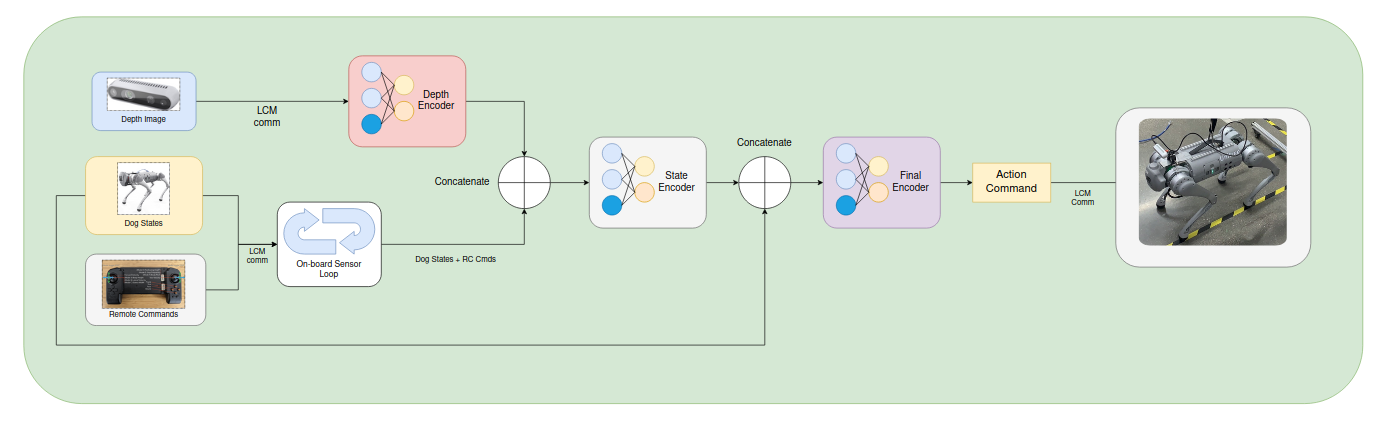
The deployment pipeline we constructed can be used for most of the quadruped projects that use camera images as input. The RL policy takes both the states of the dog and the RC Commands as input and these two information needs to be updated in real time, alongside the depth camera image; therefore, two separate processes are run, one on-board the Unitree Go1 computer to receive dog states and RC commands, and the other one on an external Nvidia Jetson Nano for performing model inference. This approach ensures that the dog will always have joint commands to execute, even during computation delay from large neural networks.
Python Wrapper for Go1 Low-level Control
I created a Python wrapper for the official Unitree Legged SDK so learning-based robot dog project can easily receive the states readings from Go1 and send joint-state actions to the dog using the Python API wrapper. The wrapper is implemented using Pybind11.
LCM Communication
The communication in the deployment is mainly implemented using Light-weight Communication and Marshalling (LCM). For example, LCM is used when trying to send dog states and RC commands messages from Go1 to Nvidia Jetson Nano; the two hosts are set to be in the same sub-net, thereby building a message sharing bridge. The sending host needs to instantiate a publisher with a custom LCM message type and publish to a topic; the receiving end needs to subscribe to the topic and a LCM message handling function needs to be running in a separate thread to process incoming messages.
The LCM communication allows us to establish message publishing and subscribing mechanisms anywhere in the conventional Python or C++ scripts, avoiding migrating the entire deep learning pipeline to ROS framework.
Training Pipeline
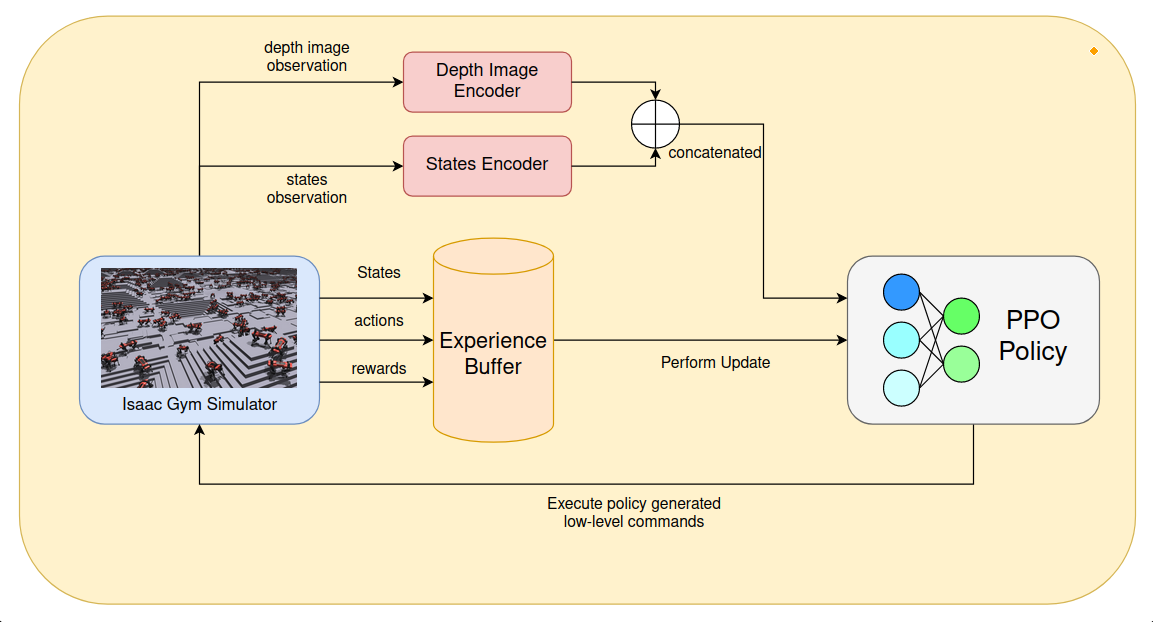
The central component of the control policy is the PPO network, which takes the proprioceptive states of the dog, depth image from camera, remote control commands, gait offset parameters as input during training (similar as deployment) As shown in the diagram above, Nvidia Isaac Gym is chosen as the physics simulator for its unique compatibility with RL related training. A large number of dogs are simulated in paralell to collectively gather trajectory roll-out for the "experience buffer", which will then be sampled to update the PPO network.
Visual Encoder
In order to fully utilize the power of large neural network and better distill the visual features in the depth images, we experimented with several models known to have a great performance in processing images: 1. the good old CNN models; 2. the Vision Transformers.
ViT Superior to CNN encoder
Convolutional Neural Network visual encoder performance
Vision Transformer encoder performance
As can be seen, the gaits generated by the visual transformer are more graceful and natural due to ViT's superior ability to extract features from images, and also because ViT's capability increases with larger network sizes while the trainability remains tractable, unlike its convolutional counterpart.
Featured Training Statistics

Here we show three important training statistics that gives us insight to the quadruped's learning curve. The reward in the first (leftmost) graph measures how well the robot dog is tracking desired leg swing patterns--higher reward means the dog's leg swing is more realistic, enabling it to move with desired styles; the second graph shows that the smoothness of the dog's action is improving as training iterations progress; the third graph describes how well the dog is tracking the desired foot-contact schedule--higher reward signifies that the dog is learning to do foot placement in a more realistic frequency.
Work Cited
This work mainly builds upon the paper walk-these-ways. The paper focuses on desigining policy that only uses proprioceptive states of the robot dog, whereas our paper tries adds in the visual information and fully utilizes the size of neural network policy; this project is still on-going and our future work includes applying large vision or language models to control quadrupeds, and the work here establishes the foundation on which future quadruped related research can be carried out easily.
For the project shown in the post, Muye created the python wrapper for Unitree's low-level control library, the LCM depth camera pipeline, the deployment code, and the training code for ViT visual encoder; Guo comes up with the idea to apply large vision model in quadruped control, writes the code for CNN visual encoder, modifies the training pipeline, and provided crucial insights in solving technical issues along the way.